Pacing Outside the Box: RNNs Learn to Plan in Sokoban

Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
Giving RNNs extra thinking time at the start boosts their planning skills in Sokoban. We explore how this planning ability develops during reinforcement learning. Intriguingly, we find that on harder levels the agent paces around to get enough computation to find a solution.

This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
Ever notice how some people pace when they're deep in thought? Surprisingly, neural networks do something similar—and it boosts their performance! We made this discovery while exploring the planning behavior of a recurrent neural network (RNN) trained to play the complex puzzle game Sokoban.
Like prior work, we train an RNN with standard model-free reinforcement learning, and give it extra thinking steps at test time.We find that without extra thinking steps, the RNN agent sometimes locks itself into an unsolvable position. However, with additional thinking time, the level is successfully mastered, suggesting that it is planning.
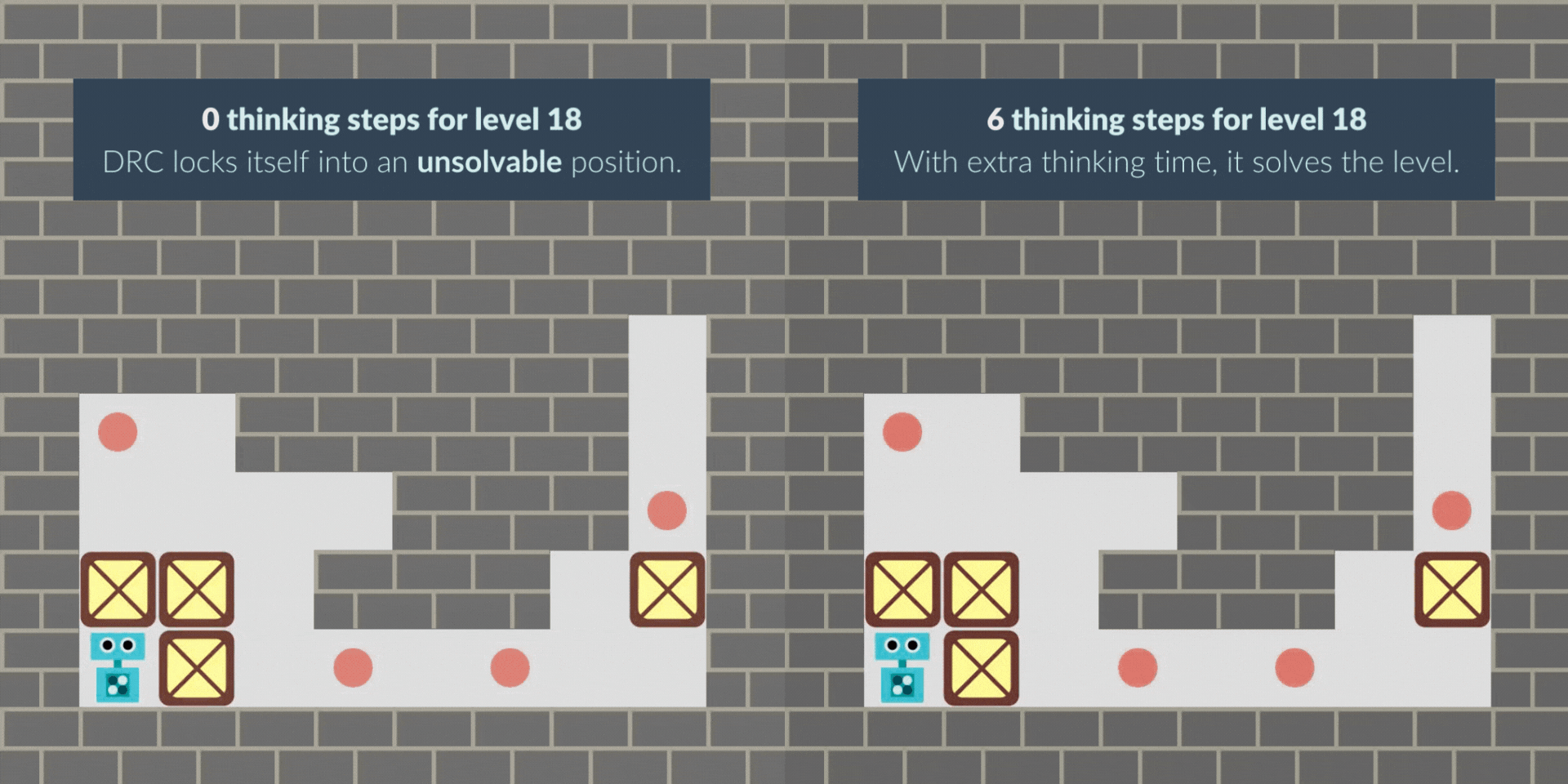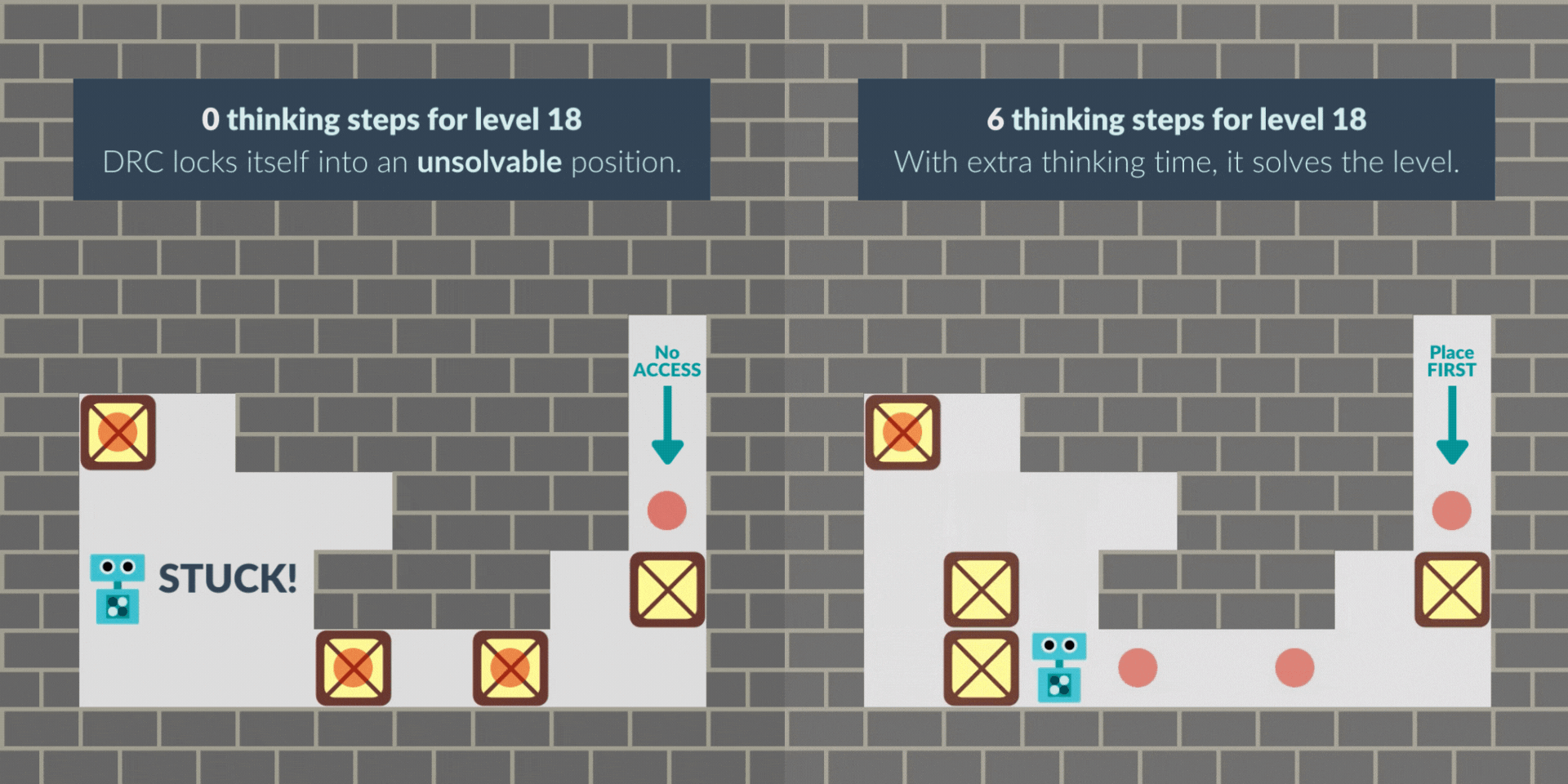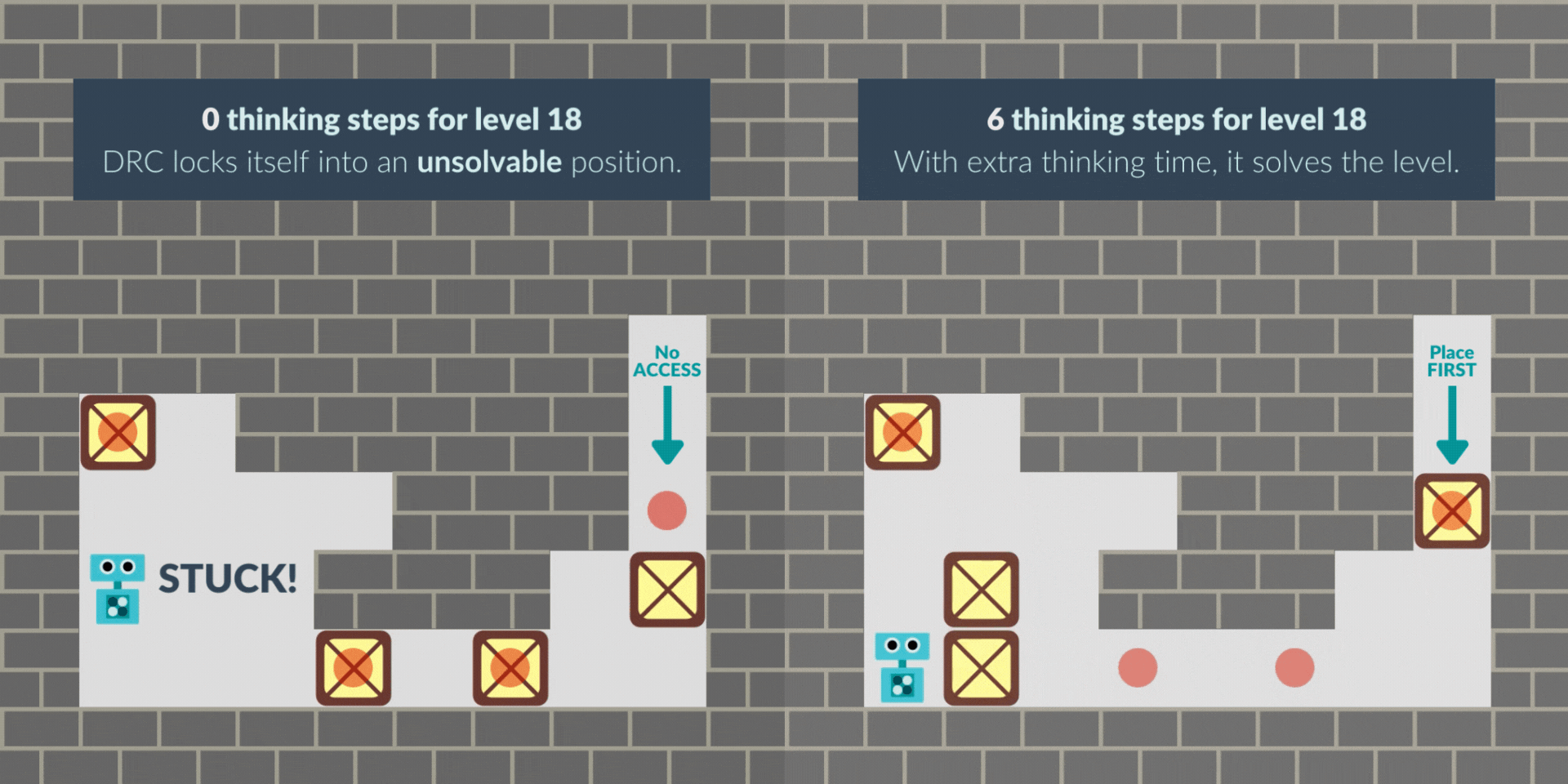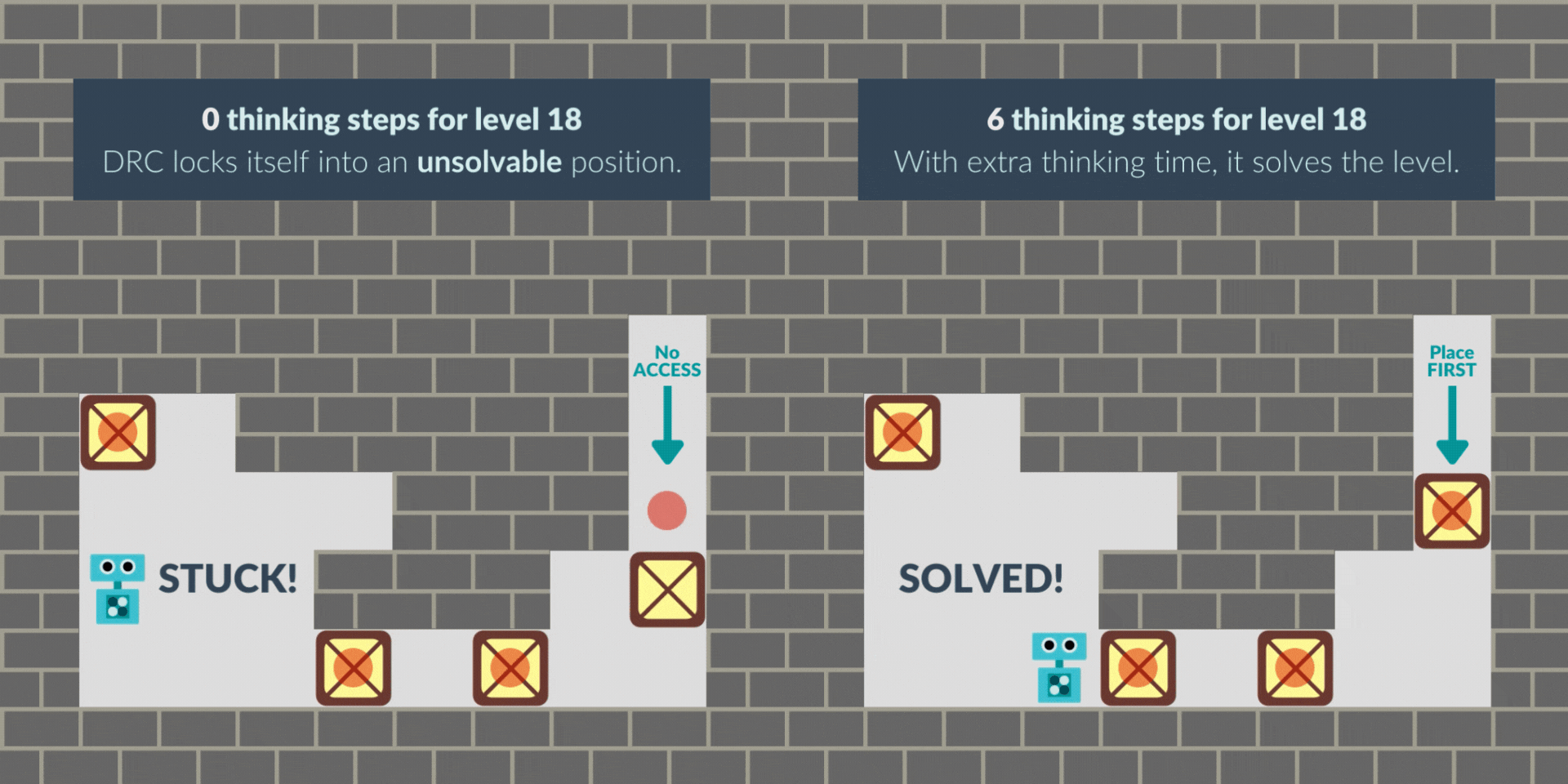
In another case, the agent starts the level by pacing around as if “buying time” when it wasn’t given extra thinking time at the beginning. With thinking time granted, its path to the solution becomes more direct and efficient, solving the puzzle faster.
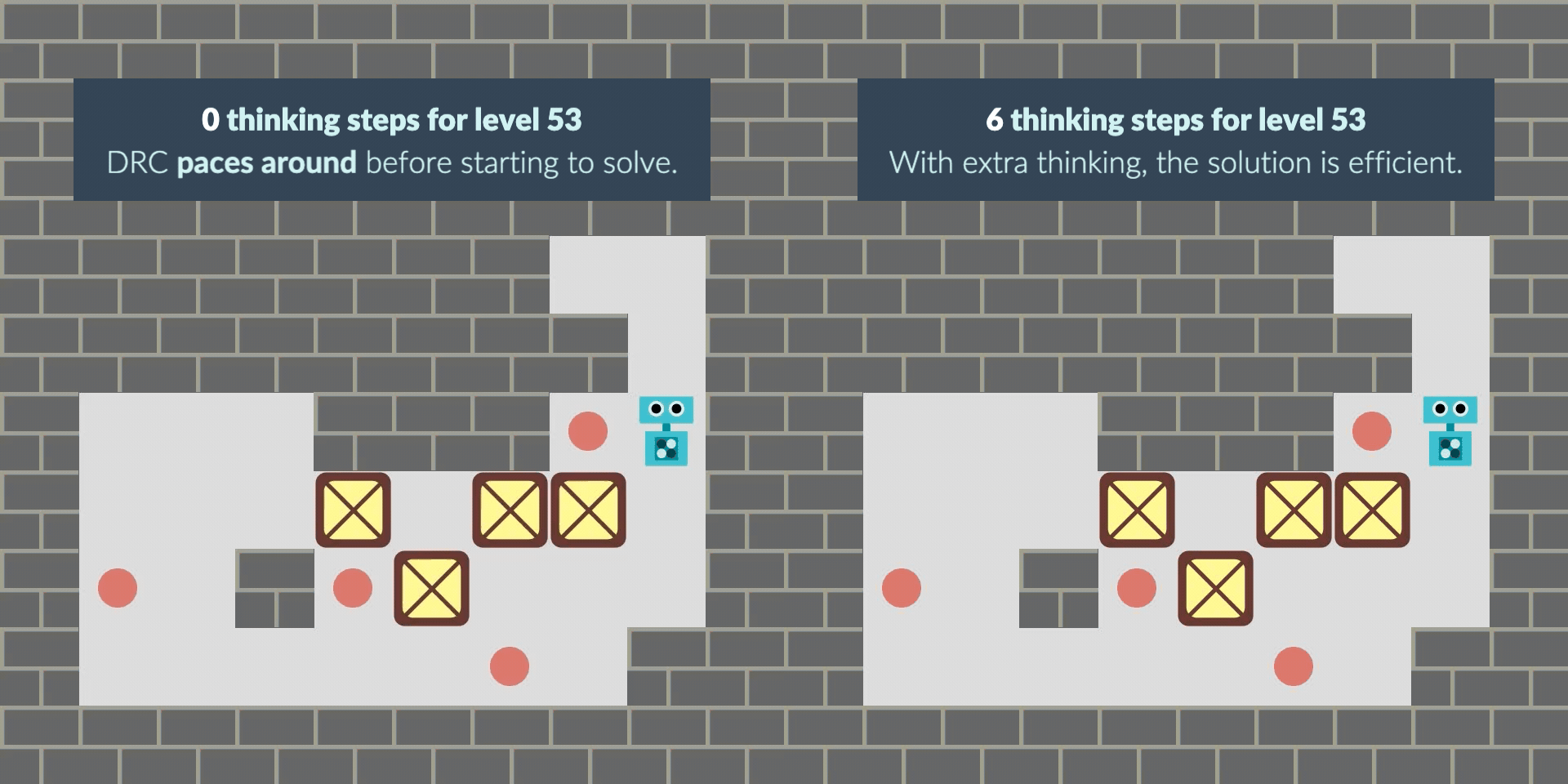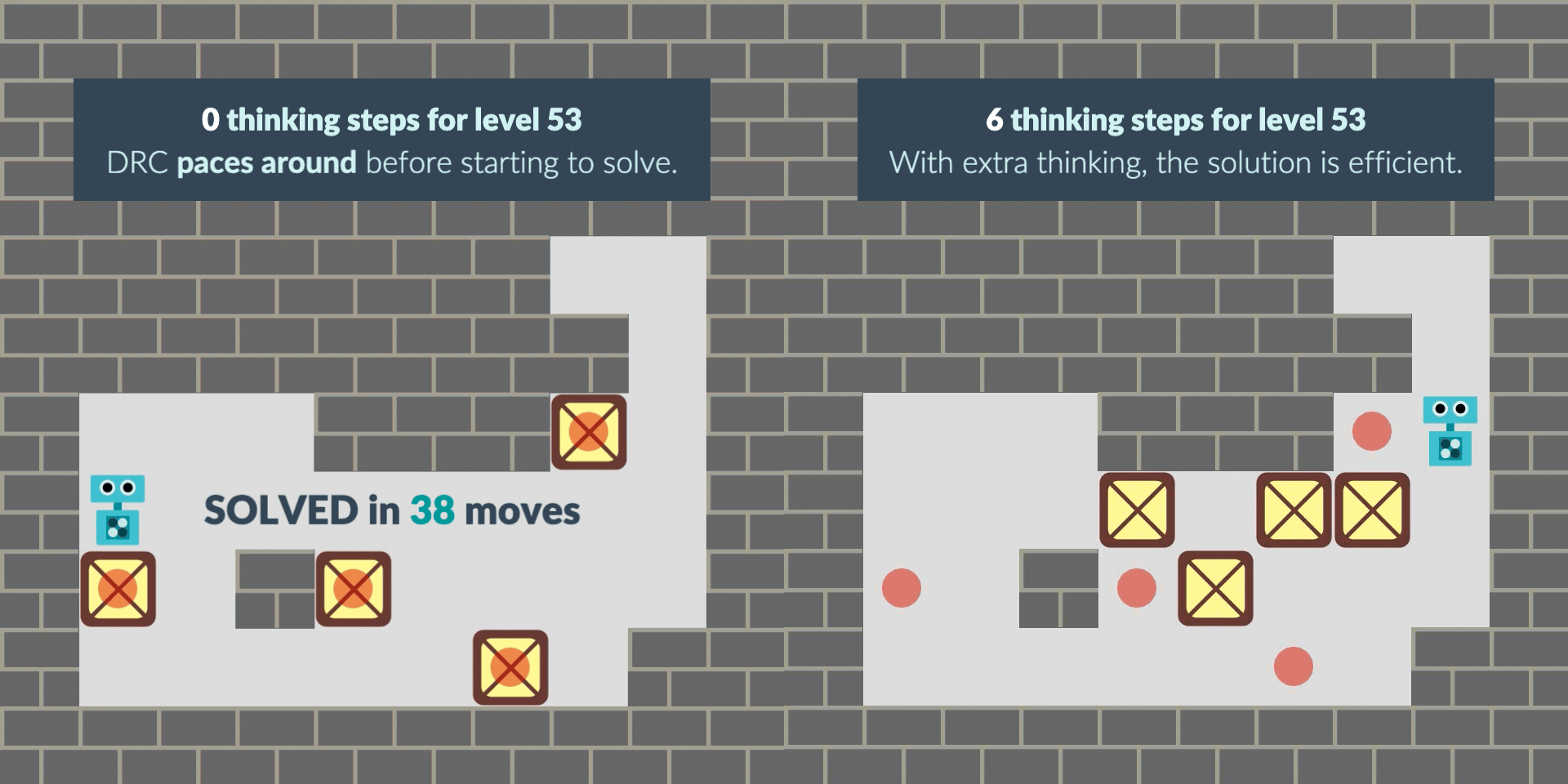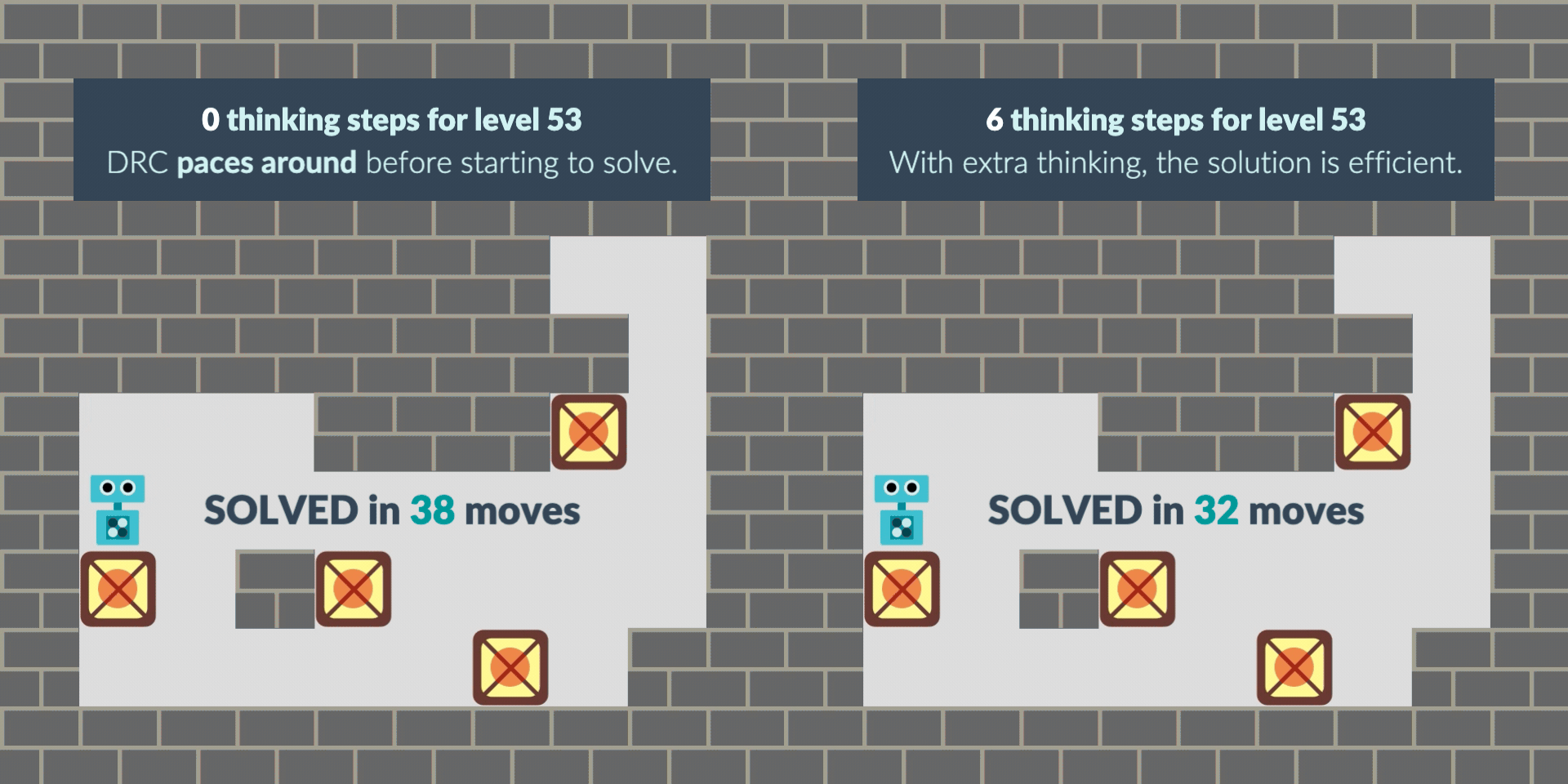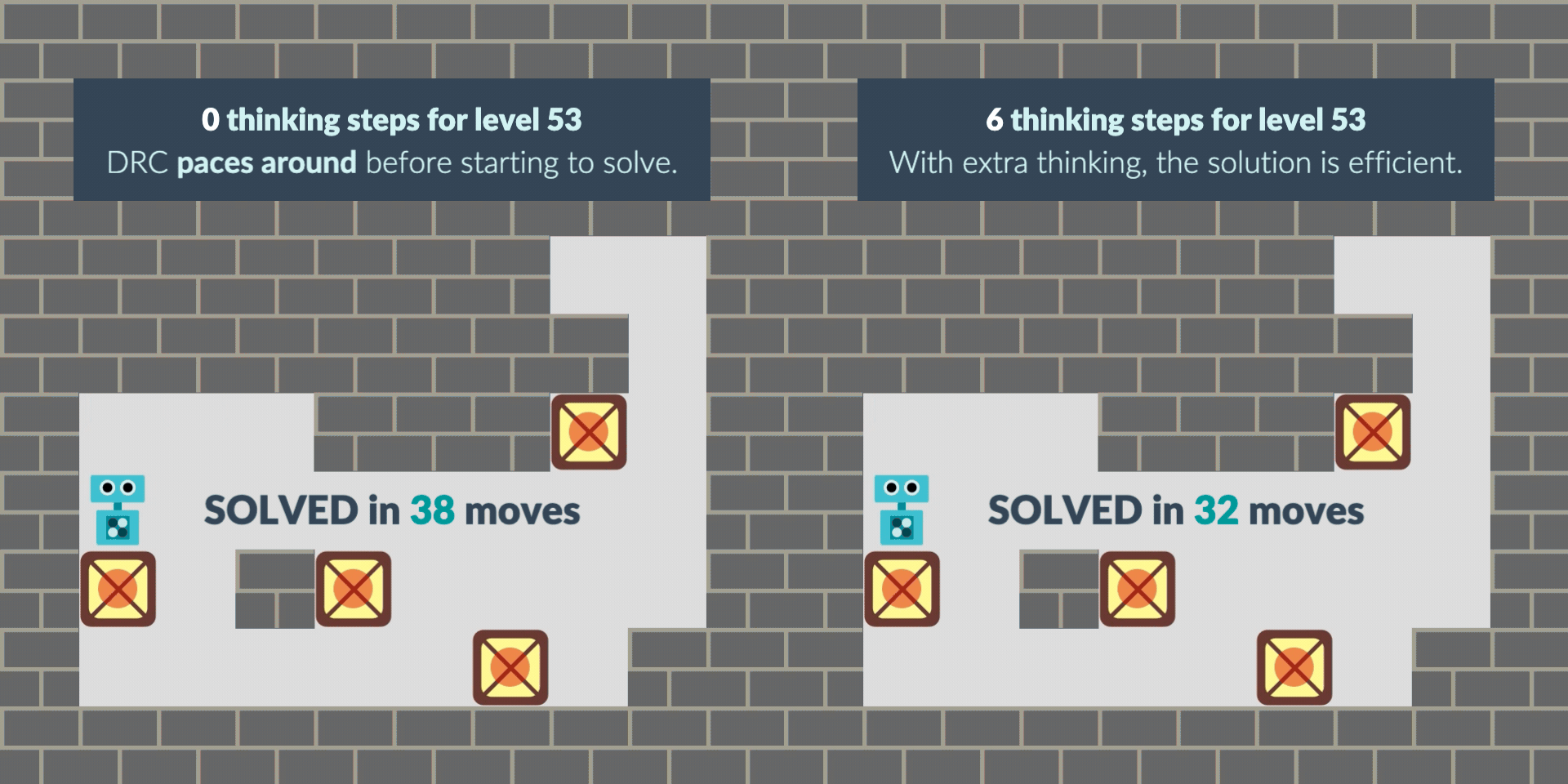
These observations raise the question: why does this intriguing behavior emerge? To find out, we conduct a detailed black-box behavioral analysis, providing novel insights into how planning behavior develops inside neural networks. However, the exact details of the internal planning process remain mysterious: we invite other interpretability researchers to study these "model organisms" of planning, open-sourcing our trained agents and source code that replicates prior work.
Understanding how neural networks reason is crucial for advancing AI and ensuring its alignment with human values, especially considering the concept of "mesa-optimizers"—neural networks that develop internal goals during training that may differ from their intended objectives. This study sheds light on the emergence of planning in deep neural networks, an important topic in AI safety debates, and provides crucial insights for developing safe and efficient AI systems.
This represents an important first step in our longer-term research agenda to automatically detect mesa-optimizers, understand their goals, and modify the goals or planning procedures to align with human values and objectives.

Training Setup
Sokoban, a classic puzzle game, is a benchmark for AI planning algorithms due to its simple rules and strategic complexity. In AI research, planning involves an agent's ability to think ahead and devise strategies to achieve a goal. This study reproduced and extended the findings of Guez et al. (2019), investigating the planning behavior of an RNN trained to play Sokoban using reinforcement learning. We trained a model with 1.28 million parameters using the Deep Repeating ConvLSTM (DRC) architecture they developed. The network was trained in a Sokoban environment with levels taken from the Boxoban dataset that comprises levels of varying difficulty, with easy levels over-represented. We pass 10x10 RGB images as input to the network and use the IMPALA algorithm to train the network. The agent received rewards for pushing boxes onto targets and a small penalty for every move, encouraging efficient planning and problem-solving. Over the course of 2 billion environment steps, the network gradually learned to plan ahead and solve puzzles effectively.

Replicating the State-of-the-Art
Our results confirm Guez et al (2019)'s findings that giving DRCs extra thinking time at the start of an episode during inference leads to enhanced planning and efficiency. In particular, we demonstrate:
- Emergent Planning Behavior: The DRC agent demonstrated strategic thinking, benefiting greatly from additional thinking time early in training.
- Improved Performance with Thinking Time: With more thinking steps, the DRC agent solved puzzles more efficiently and outperformed a non-recurrent ResNet baseline, especially on complex puzzles.
- Training and Architecture Details: The DRC architecture, with its convolutional LSTM layers, proved effective for our Sokoban tasks, outperforming the non-recurrent ResNet baseline (orange). The training process, powered by the IMPALA algorithm, achieved strong performance – preliminary experiments with PPO yielded a substantially lower level solution rate.
Behavioral Analysis
Planning Solves More Levels: More thinking steps (x-axis, below) improved the success rate of the DRC agent up to 6 steps, after which it plateaued or slightly declined. The recurrent DRC agent substantially outperforms the non-recurrent ResNet baseline, even though the ResNet had more than 2x the parameters of the DRC agent, further demonstrating the utility of planning.

Solving Harder Levels: If extra thinking steps enable new levels to be solved, what’s special about those new levels? We analyze the average length of the optimal solution (not necessarily the one played by the DRC agent) for levels first solved at a given number of thinking steps. We find that levels requiring more thinking steps tend to have a higher optimal solution length, indicating those levels are harder than average. We conjecture that more thinking steps enabled the DRC agent to solve these harder levels by taking strategic moves that pay-off in the long run, avoiding actions that are myopically good but cause the level to become unsolveable (e.g. getting a box “stuck”).

Efficient Box Placement: Evidence for the above conjecture is provided by the plot to the right, below. In levels that are solved with 6 thinking steps, but not 0 steps, the time taken to place the first three boxes (B1, B2, B3) actually increases – the agent is seemingly less efficient. However, the time taken to place the final fourth box (B4) decreases. This suggests the agent is taking actions that are better in the long-run, enabling more levels to be solved (figure above) and faster (figure below) – but only by delaying the instantaneous gratification of placing the first few boxes.

Cycle Reduction: 82.39% of cycles, or agent “pacing” behavior, disappeared when the network was made to think for N steps before starting an N-length cycle. This confirms that the network uses these cycles to formulate a plan.

Implications & Conclusion
Just like people who pace to think through tough problems, neural networks benefit from a bit of 'pacing' or time to plan ahead for challenging tasks like solving Sokoban. Understanding how this planning behavior emerges in networks can help develop more resilient and reliable AI systems. Additionally, these insights can improve the interpretability of AI decision-making, making it easier to diagnose and address potential issues.
By revealing how neural networks develop planning strategies, we aim to provide insights that contribute to AI alignment and help reduce the risk of harmful misgeneralization. This work presents a promising model for further exploration into mechanistic interpretability and AI safety. Ultimately, this study contributes to the broader goal of creating trustworthy and aligned AI systems that can think ahead, plan effectively, and align with human values.
For more information, read our full paper “Planning behavior in a recurrent neural network that plays Sokoban.” If you are interested in working on problems in AI safety, we’re hiring. We're also open to exploring collaborations with researchers at other institutions -- just reach out at hello@far.ai.