Beyond the Board: Exploring AI Robustness Through Go
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
June 17, 2024
Summary
Achieving robustness remains a significant challenge even in narrow domains like Go. We test three approaches to defend Go AIs from adversarial strategies. We find these defenses protect against previously discovered adversaries, but uncover qualitatively new adversaries that undermine these defenses.
Last year, we showed that supposedly superhuman Go AIs can be beaten by human amateurs playing specific “cyclic” patterns on the board. Vulnerabilities have previously been observed in a wide variety of sub- or near-human AI systems, but this result demonstrates that even far superhuman AI systems can fail catastrophically in surprising ways. This lack of robustness poses a critical challenge for AI safety, especially as AI systems are integrated in critical infrastructure or deployed in large-scale applications. We seek to defend Go AIs, in the process developing insights that can make AI applications in various domains more robust against unpredictable threats.

We explored three defense strategies: positional adversarial training on handpicked examples of cyclic patterns, iterated adversarial training against successively fine-tuned adversaries, and replacing convolutional neural networks with vision transformers. We found that the two adversarial training methods defend against the original cyclic attack. However, we also found several qualitatively new adversarial strategies (pictured below) that can overcome all these defenses. Nonetheless, finding these new attacks is more challenging than against an undefended KataGo, requiring more training compute resources for the adversary.



Background
The ancient board game Go has become a popular testing ground for AI development thanks to its simple rules that nonetheless lead to significant strategic depth. The first superhuman Go AI, AlphaGo, defeated top player Lee Sedol in 2016. We now test KataGo, an open-source model that’s even more powerful. These AIs search over possible moves and counter-moves using Monte Carlo Tree Search (MCTS), guided by a neural network that proposes moves and evaluates board states. The neural network is learned through self-play games where the AI competes against itself to refine its decision-making without human input. The resulting AI’s strength is influenced by the visit count: the number of moves evaluated during the search, with higher counts leading to stronger gameplay.
While KataGo excels under standard conditions, we previously found that both KataGo and other superhuman Go AIs can be exploited and can falter when faced with “adversarial attacks”—unexpected strategies that exploit algorithmic blind spots—such as the “cyclic attack” pictured below. This raises a crucial question: as KataGo wasn’t designed with adversarial attacks in mind, are there straightforward ways to enhance its robustness against such exploits? We explore three possible defenses in the following sections.

Positional Adversarial Training
The first approach, positional adversarial training, integrates hand-curated adversarial positions directly into the training data, aiming to preemptively expose and strengthen the AI against known weaknesses. This approach has been taken by KataGo’s developers since we disclosed the original cyclic exploit in December 2022. In particular, the developers have added a mixture of positions from games played against our cyclic adversary, as well as other cyclic positions identified by online players.
This approach has been successful at defending against the original cyclic adversary. However, we were readily able to train a new adversary to beat the latest KataGo model as of December 2023 using a cyclic-style attack (pictured below). This attacker achieved a 65% win rate against KataGo playing with 4096 visits and a 27% win rate at 65,536 visits. This suggests that while attacks are harder to execute against this latest model, its defenses are still incomplete.


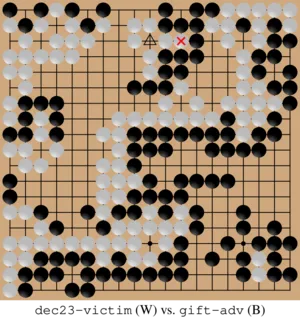
Additionally, we discovered a new non-cyclic vulnerability that we named the “gift attack” as KataGo inexplicably lets the adversary capture two stones. This qualitatively new vulnerability illustrates the challenge of securing AI against evolving adversarial tactics.
Example of new "gift attack"
The "gift attack" adversary (Black) creates a sending-two-receiving-one situation that induces KataGo (White) to play at the location marked with a triangle (left board, below), inexplicably offering the adversary a gift of two stones. On the right, the adversary immediately captures these two stones. KataGo then attempts to play at the triangle-marked location to recapture—but is prevented by the superko rule, which prohibits repeating a previous board position. This restriction allows the adversary to secure a key position, resurrecting their entire group in that area and leading to a significant reversal in the game.

Iterated Adversarial Training
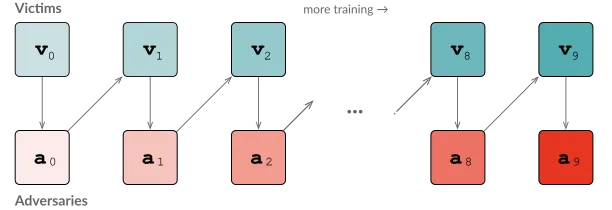
Iterated adversarial training improves KataGo’s robustness by engaging in a continuous cycle of attack and defense. This process starts with a “victim” KataGo network v0 not previously exposed to adversarial training. Each cycle involves two phases. First, an adversary an is trained to overcome the victim vn’s defenses. Next, the KataGo “victim” vn+1 is fine-tuned to defend against the previously identified adversarial attack an.This process mirrors the ongoing arms race typical in cybersecurity defenses.
We found each victim vn+1 learns to be robust to the adversary that it was trained against, as well as all previous adversaries—including the original cyclic attack. However, this robustness does not transfer to unseen adversaries. The final iteration of the defended victim v9 playing at a very superhuman 65,536 visits is beaten 42% of the time by the new a9 attacker.


Example of new "atari attack"

We also trained an attacker from an early checkpoint of the original cyclic adversary, directly against a9 and without the sequential fine-tuning process of the an adversaries. The resulting attack is cyclic but with the distinctive tendency to leave many stones and groups in “atari”, i.e. that could be captured on the next move by the victim. Moreover, it sets up “bamboo joints” (above): shapes where one player (in this case, white) has two pairs of stones with a two-space gap between them. They are common in normal play, and usually strong shapes: if black plays either triangle-marked location △, white can play the other to keep the joints connected. However, the adversary weaponizes this usually innocuous pattern, inducing the victim to form a large cyclic group including these bamboo joints (below).

Vision Transformer
Traditionally, superhuman Go AIs, including AlphaGo and its successors, have relied on convolutional neural networks (CNNs). We experimented with Vision Transformers (ViTs) to see if a shift in neural network architecture could mitigate the cyclic vulnerabilities. CNNs process spatially local data, so they may struggle with cyclic patterns in Go that are larger than their local visual field. By contrast, ViTs process information from the entire image simultaneously. This benefit, combined with ViT’s proven success in various image domains, led us to hypothesize that ViTs might better handle the complexities of adversarial attacks in Go.
We trained a new ViT-based Go bot to superhuman levels. Surprisingly, it remained vulnerable to the original cyclic attack at low visit counts (playing at a professional but not superhuman level). Moreover, after fine-tuning the adversary was also able to beat the ViT bot playing at visit counts high enough for superhuman performance. This result suggests that the vulnerability to cyclic attacks extends beyond a specific neural architecture, potentially implicating deeper issues such as the strategic dynamics inherent in the game or the self-play training paradigm, which might reinforce certain predictable patterns that adversaries can exploit.


Conclusion
Our exploration of adversarial robustness in Go has revealed significant challenges for securing AI against attacks, even in an environment that might seem potentially straightforward. All three defenses tested could be overcome by new attacks, highlighting the complexity of achieving robustness. This difficulty in Go suggests even greater challenges in more complicated real-world scenarios. These findings underscore the limitations of current strategies and suggest the need for more sophisticated techniques. Methods such as latent adversarial training or more sophisticated reinforcement learning algorithms may enhance AI’s ability to generalize from adversarial data and handle complex scenarios beyond the game board.
For more information, visit the project website and read our full paper. If you are interested in working on improving AI robustness, we’re hiring and also interested in exploring collaborations with researchers at other institutions: feel free to reach out to hello@far.ai.
