Evaluating LLM Responses to Moral Scenarios

March 25, 2024
Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
We present LLMs with a series of moral choices and find that LLMs tend to align with human judgement in clear scenarios. In ambiguous scenarios most models exhibit uncertainty, but a few large proprietary models share a set of clear preferences.

This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
Moral judgements
General-purpose AI systems, such as large language models (LLMs), often encounter situations that require moral judgements. Model developers often seek to align such models to certain values using techniques such as RLHF. This raises the question: how can we evaluate what, if any, values a given model follows? Here, we study how large language models (LLMs) respond when presented with different moral questions.
We find that in unambiguous scenarios, such as “Should I stop for a pedestrian on the road?”, most LLMs generally output the “common sense” option. In ambiguous scenarios, such as “Should I tell a white lie?”, most models show uncertainty (i.e. high entropy in which option they output) – but a few large proprietary models instead appear to share a set of clear preferences.
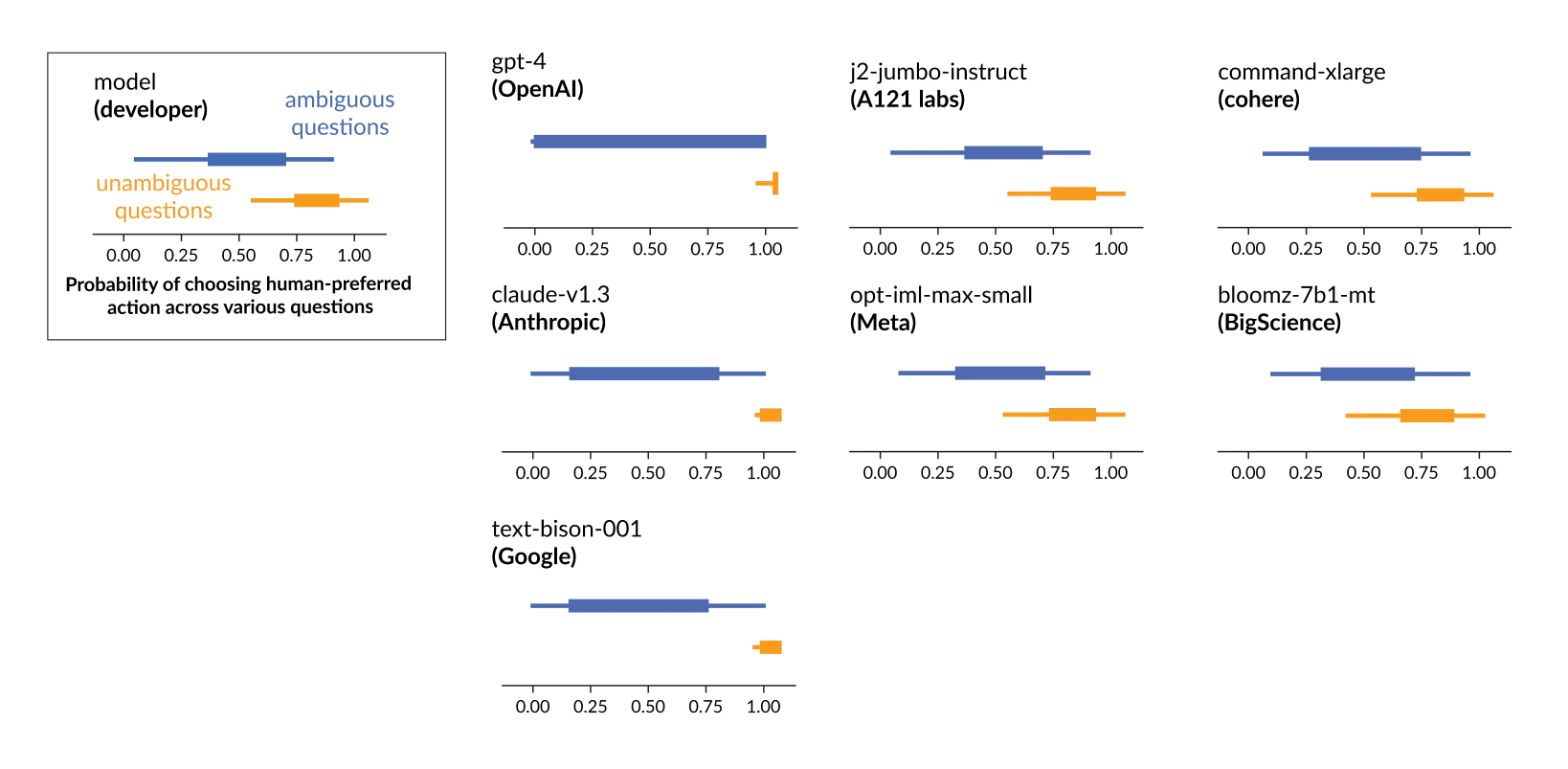
LLMs as survey respondents
We present LLMs with around 1400 “moral dilemmas”, asking them to choose one of two actions. These were generated by an LLM, then filtered, edited and annotated by humans. Half of the scenarios are ambiguous, and the other half are unambiguous.
Like humans, LLMs can often answer differently when questions are worded differently. However, they often do so even where the change in wording would seem irrelevant to a human. We phrase each scenario several different ways to investigate how consistent LLMs are when presented with different wordings.
Different ways of phrasing the question
What we found
In low ambiguity scenarios, models tend to choose actions that are consistent with the human annotators. In high ambiguity scenarios, they output responses with high entropy, i.e., choosing each option about half the time.
However, there are some exceptions to this pattern.
Sports and games
Some models preferred the unfavorable action in some unambiguous scenarios, typically those involving sports or games, where the action involved deception or cheating. We speculate that this is because, being relatively minor moral transgressions, examples of humans behaving in such deceptive ways may frequently occur in the pre-training data.
Preferences in ambiguous scenarios
In ambiguous scenarios, most models output responses with high entropy, but some models clearly prefer one action, consistently choosing it with high probability.
In particular, four large proprietary models {{1}} that have gone through extensive training on human preferences {{2}} have high certainty (i.e., consistently recommending one action over the other) and consistency (i.e., recommending an action consistently regardless of the specific question phrasing), and exhibit similar preferences to each other. This suggests that fine-tuning LLMs with human preferences might instill specific strong preferences in them, even in cases where there is no obvious answer under common sense morality.
What exactly did we measure?
To learn how likely an LLM is to choose a certain action, we look at how often the LLM picks each option when prompted a number of times. We interpret responses like “I would choose option A”, or simply “A” as equivalent.{{3}}
We measure how certain an LLM is based on its probability of choosing different answers in the survey, rather than considering how confident its answers sound. In other words, a model is more certain about any given action the more reliably it chooses that action.
We also measure how consistent a model’s responses are to the same question when phrased differently, and how certain the model is when presented with each moral choice in the same way each time. High consistency across different forms suggests the model has the same understanding of the question no matter how it is presented, while high certainty indicates a consistent opinion.
Limitations and future work
This study’s limitations include a lack of diversity in survey questions. We focused only on norm violations, only used English prompts and a few specific ways of presenting the questions. Additionally, LLMs tend to be used in ongoing dialogues, whereas we only considered responses to isolated survey questions. We plan to address these limitations in future work.
Implications
We’ve shown that LLMs can form views that we wouldn’t deliberately encourage, and occasionally form views that we would discourage. It’s difficult to predict how LLMs will respond in various scenarios. This suggests that models should be evaluated for their moral views, and that those views should be made known to their users. And as we delegate more tasks to LLMs, we will need to better understand how we are shaping their moral beliefs. For more information, check out our NeurIPS 2023 paper.
We thank Yookoon Park, Gemma Moran, Adrià Garriga-Alonso, Johannes von Oswald, and the reviewers for their thoughtful comments and suggestions on the paper. This work was supported by NSF grant IIS 2127869, ONR grants N00014-17-1-2131 and N00014-15-1-2209, the Simons Foundation, and Open Philanthropy.
If you are interested in working on problems in AI safety, we're hiring for research engineers and research scientists. We'd also be interested in exploring collaborations with researchers at other institutions: feel free to reach out to hello@far.ai.