2023 Alignment Research Updates

November 21, 2023
Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
Highlights from FAR.AI’s alignment research in 2023. Our science of robustness agenda has found vulnerabilities in superhuman Go systems; our value alignment research has developed more sample-efficient value learning algorithms; and our model evaluation direction has developed a variety of new black-box and white-box evaluation methods.

This is a div block with a Webflow interaction that will be triggered when the heading is in the view.
FAR.AI is a non-profit AI safety research institute, working to incubate a diverse portfolio of research agendas. We’ve been growing rapidly and are excited to share some highlights from our research projects since we were founded just over a year ago. We’ve also been busy running field-building events and setting up a coworking space – see our overview post for more information on our non-research activities.
Our Mission
We need safety techniques that can provide demonstrable guarantees of the safety of advanced AI systems. Unfortunately, currently deployed alignment methods like Reinforcement Learning from Human Feedback (RLHF) fall short of this standard. Proposals that could provide stronger safety guarantees exist but are in the very early stages of development.
Our mission is to incubate and accelerate these early-stage approaches, so they can be empirically tested and deployed. We focus on research agendas that are too large to be pursued by individual academic or independent researchers but are too early-stage to be of interest to most for-profit organizations.
We take bets on a range of these promising early-stage agendas and then scale up those that prove most successful. Unlike other research organizations that take bets on specific agendas, our structure allows us to both (1) explore a range of agendas and (2) execute them at scale. Our current bets fall into three categories:

Science of Robustness: How does robustness vary with model size? Will superhuman systems be vulnerable to adversarial examples or “jailbreaks” similar to those seen today? And, if so, how can we achieve safety-critical guarantees?
Value Alignment: How can we learn reliable reward functions from human data? Our research focuses on enabling higher bandwidth, more sample-efficient methods for users to communicate preferences for AI systems; and improved methods to enable training with human feedback.
Model Evaluation: How can we evaluate and test the safety-relevant properties of state-of-the-art models? Evaluation can be split into black-box approaches that focus only on externally visible behavior (“model testing”), and white-box approaches that seek to interpret the inner workings (“interpretability”). These approaches are complementary, with black-box approaches less powerful but easier to use than white-box methods, so we pursue research in both areas.
Science of Robustness
, we found that superhuman Go AIs such as KataGo are vulnerable to adversarial attacks.](https://cdn.prod.website-files.com/66f6ee23e5732cc3b38ca38e/6765d121216d64ba1d31e3a8_671e32287adf0a7e3c24ba84_threat_model.svg)
No engineered component is indestructible. When designing physical structures, engineers estimate how much stress each component needs to withstand, add an appropriate safety margin, and then choose components with the appropriate tolerance. This enables safe and cost-effective construction: bridges rarely fall down, nor are they over-engineered.
AI components such as LLMs or computer vision classifiers are far from indestructible, being plagued by adversarial examples and vulnerability to distribution shift. Unfortunately, AI currently has no equivalent to the stress calculations of civil engineers.
So far the best approach we have is to guess-and-check: train a model, and then subject it to a battery of tests to determine its capabilities and limitations. But this approach gives little theoretical basis for how to improve systems. And both the training and testing of models are increasingly expensive and labor-intensive (with the cost of foundation model training now rivaling that of the construction of bridges).
We want to develop a more principled approach to building robust AI systems: A science of robustness. Such a science would allow us to answer fundamental questions about the future, such as whether superhuman AI systems will remain vulnerable to adversarial examples that plague contemporary systems. It would also enable practitioners to calculate how much adversarial training is needed to achieve the level of robustness required for a given application. Finally, if current robustness techniques prove insufficient, then the science would help researchers develop improved training techniques and reduce stresses on components by utilizing a defense in-depth approach.
Our CEO Adam more thoroughly explored the importance of robustness to avoiding catastrophic risks from advanced AI systems in AI safety in a world of vulnerable machine learning systems. Since then, a team headed by Tony Wang demonstrated, in an ICML paper, that superhuman Go AI systems like AlphaGo exhibit catastrophic failure modes. We are currently investigating iterated adversarial training and alternative network architectures to determine if this weakness can be eliminated, leading to an improved qualitative understanding of the difficulty of making advanced ML systems robust.
Adrià Garriga-Alonso and others are starting to investigate why AlphaGo-style systems are vulnerable to our adversarial attack using a mechanistic interpretability approach. We are considering interpretability techniques like activation patching and automatic circuit discovery to identify the key representations and computations inside these networks that lead to the mistake. This understanding could help fix the networks by editing them manually, fine-tuning, or changing the architecture.
To gain a more quantitative understanding of robustness, Adam Gleave, Niki Howe and others are searching for scaling laws for robustness in language models. Such scaling laws could help us predict whether robustness and capabilities will converge, stay a fixed width apart or diverge as compute and training data continues to grow. For example, we hope to measure to what degree the sample efficiency of adversarial training improves with model size. Ultimately, we hope to be able to predict whether for a given task and training setup, how many FLOPs of compute would be required to find an instance that the model misclassifies. To find these scaling laws, we are currently studying language models fine-tuned to classify simple procedurally defined languages, with varying degrees of adversarial training.
In the long run, we hope to leverage these scaling laws to both quantitatively find ways to improve robust training (looking to see if they improve the scaling curve, not just a single data point on the curve), as well as adapt alignment approaches to reduce the adversarial optimization pressure exerted below the robustness threshold that contemporary techniques can achieve.
Value Alignment
We want AI systems to act in accordance with our values. A natural way to represent values is via a reward function, assigning a numerical score to different states. One can use this reward function to optimize a policy using reinforcement learning to take actions that lead to states deemed desirable by humans. Unfortunately, manually specifying a reward function is infeasible in realistic settings, making it necessary to learn reward functions from human data. This basic procedure is widely used in practical applications, with variants of Reinforcement Learning from Human Feedback used in frontier models such as GPT-4 and Claude 2.
Value learning must result in reward models that specify the user’s preferences as accurately as possible, since even subtle issues in the reward function can have dangerous consequences. To this end, our research focuses on enabling higher bandwidth, more sample-efficient methods for users to communicate their preferences to AI systems, and more generally improving methods for training with human feedback.
A team led by Scott Emmons found that language models at least exhibit some understanding of human preferences: GPT-3 embeddings contain a direction corresponding to common-sense moral judgments! This suggested to us that the model’s understanding may be good enough to at least be able to express preferences in the form of natural language. To that end, Jérémy Scheurer and others developed a method to learn a reward function from language feedback. With this one can fine-tune a model to summarize with only 100 samples of human feedback. We found that this method is especially useful for improving code generation.
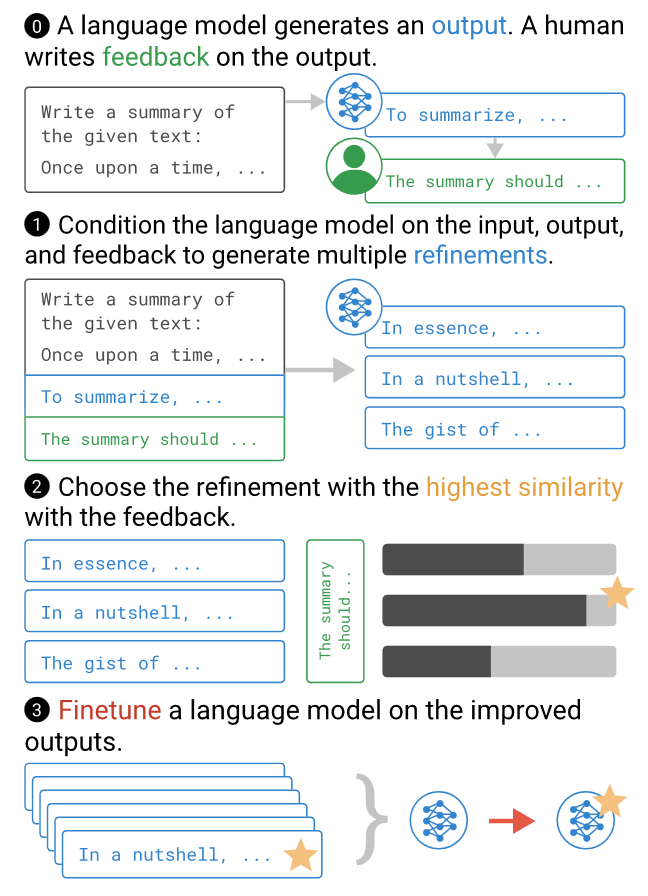
We also wanted to extend this method to other modalities besides language. A team led by Juan Rocamonde were able to successfully apply our language model feedback approach to robotics policies, by using the image captioning model CLIP to “translate” language feedback into a reward for image-based observations.
Model Evaluation
We need ways of testing how safe a model is. This is required both to help researchers develop safer systems and to validate the safety of newly developed systems before they are deployed.
At a high level, evaluation can be split into black-box approaches that focus only on externally visible model behavior (“model testing”), and white-box approaches that seek to interpret the inner workings of models (“interpretability”).
Since we ultimately care about the external behavior of these models, black-box methods are the natural method to find failures. But they don’t tell us why failures take place. By contrast, white-box evaluations could give us a more comprehensive understanding of the model, but are considerably harder to implement. We see these approaches as complementary, so we are pursuing them in parallel.
Black-Box Evaluation: Model Testing
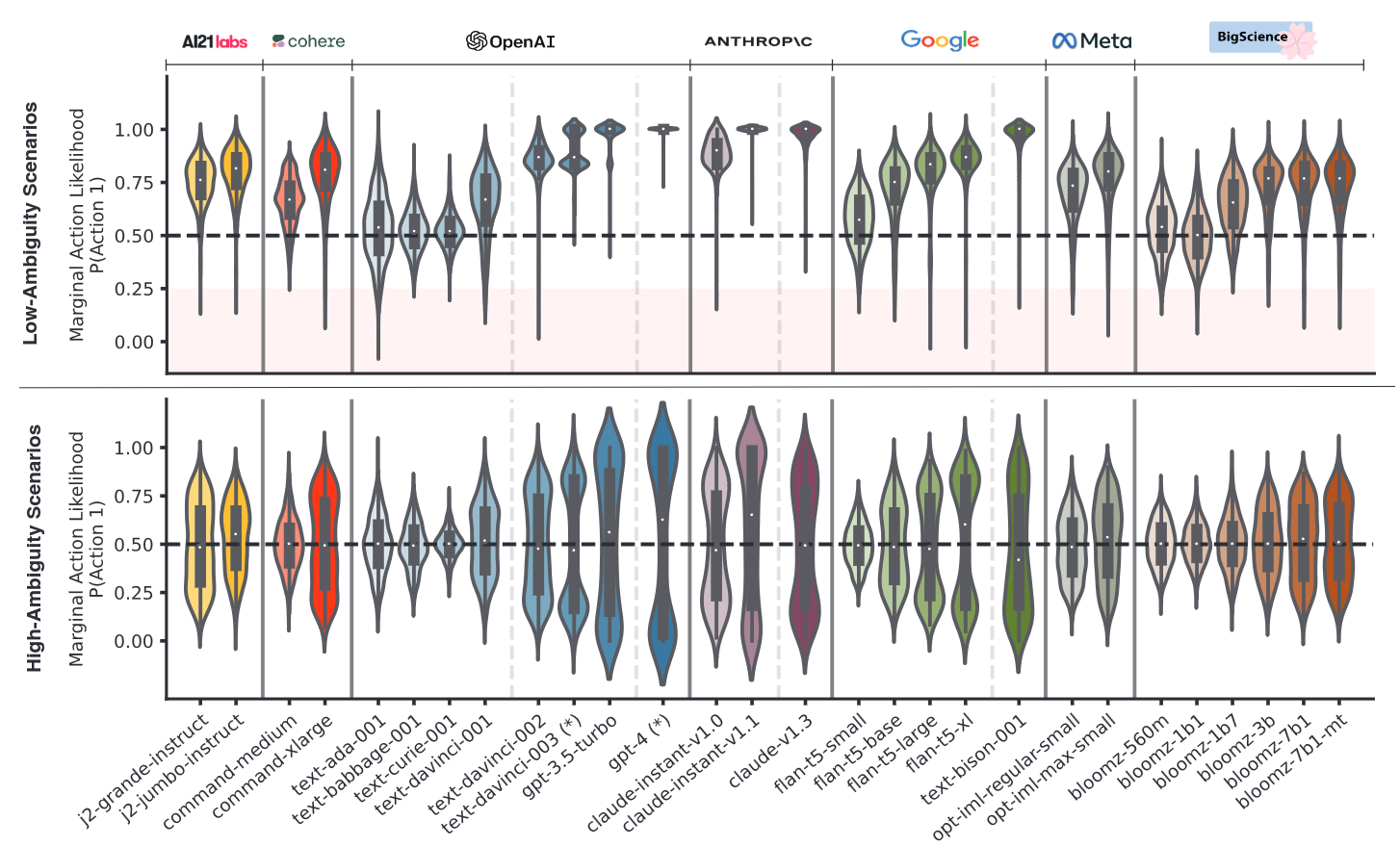
Ian McKenzie and others investigated inverse scaling: tasks where larger models do worse than smaller models. Such instances are significant as the problem would be expected to worsen over time with model capabilities, requiring explicit safety research to address. Fortunately, we found only limited such examples, and work by Wei et al (2022) building on our results found that in many cases the scaling is really “U-shaped”, with performance decreasing with model size initially but then improving again past a certain threshold of model size.
A team led by Nino Scherrer evaluated the moral beliefs of LLMs, finding that in cases humans would find unambiguous, LLMs typically choose actions that align with common-sense moral reasoning. However, in ambiguous cases where humans disagree, some models still reflect clear preferences that vary between models. This suggests LLMs in some cases exhibit “mode collapse”, confidently adopting certain controversial moral stances.
White-Box Evaluation: Interpretability
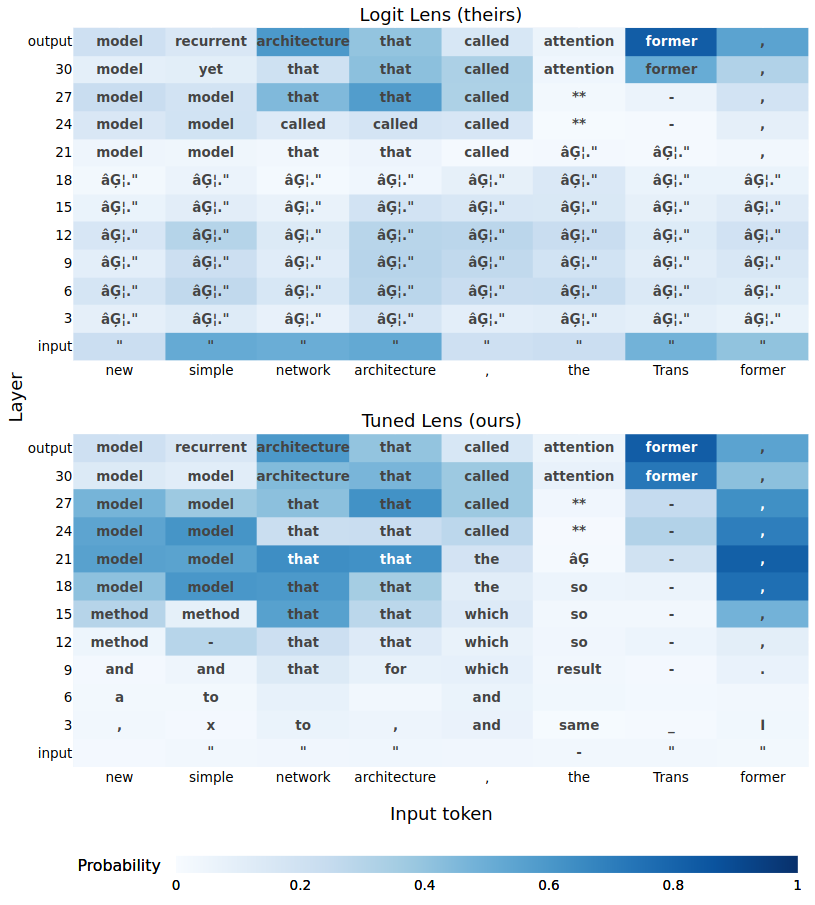
A team led by Nora Belrose developed the tuned lens technique to interpret activations at each layer of a transformer as being about predictions of the next token. This can be easily applied to a variety of models to achieve a coarse-grained understanding of the model, such as which layers implement a given behavior (like induction heads that copy from the input stream).
Mohammad Taufeeque and Alex Tamkin developed a method to make neural networks more like traditional computer programs by quantizing the network’s continuous features into what we call codebook features. We finetune neural networks with a vector quantization bottleneck at each layer. The result is a network whose intermediate activations are represented by the sum of a small number of discrete vector codes chosen from a codebook. Remarkably, we find that neural networks can operate under this stringent bottleneck with only modest degradation in performance.
)](https://cdn.prod.website-files.com/66f6ee23e5732cc3b38ca38e/6765d1218f193de909df256b_671c15baf31fb92ef5d1ba93_codebook_features_summary.webp)
Adrià Garriga-Alonso is at the early stages of understanding how ML systems learn to plan. Neural networks perform well at many tasks, like playing board games or generating code, where planning is a key component of human performance. But these networks also frequently fail in ways quite different to humans. We suspect this discrepancy may be due to differences in how the networks plan and represent concepts. This issue is particularly important to safety since a system that has learned to plan might take capable but misaligned actions off-distribution: the problem of goal misgeneralization.
In the future, we hope to work towards a science of interpretability by asking the question: how well does a hypothesis explain model behavior? At present, there are numerous competing proposals, none of which have a principled definition. We will first develop a taxonomy of algorithms to test interpretability hypotheses. Then we will define several tasks interpretability should help in, such as the ability of a human to “simulate” how a model behaves, and investigate how different metrics predict how well a given hypothesis helps in the performance of that task.
We are excited to see where the above research directions take us, but we do not plan on limiting our work to these areas. We are always on the lookout for promising new ways to ensure advanced AI systems are safe and beneficial.
How can I get involved?
We’re hiring!
We’re currently hiring research scientists, research engineers and communication specialists. We are excited to add as many as five technical staff members in the next 12 months. We are particularly eager to hire senior research engineers, or research scientists with a vision for a novel agenda, although we will also be making several junior hires and would encourage a wide range of individuals to apply. See the full list of openings and apply here.
We’re looking for collaborators!
We frequently collaborate with researchers at other academic, non-profit and – on occasion – for-profit research institutes. If you’re excited to work with us on a project, please reach out at hello@far.ai.
Want to donate?
You can help us ensure a positive future by donating here. Additional funds will enable us to grow faster. Based on currently secured funding, we would be comfortable expanding by 1-2 technical staff in the next 12 months, whereas we would like to add up to 5 technical staff. We are very grateful for your help!
Want to learn more about our research?
Have a look at our list of publications and our blog. You can also reach out to us directly at hello@far.ai.
We look forward to hearing from you!