Codebook Features: Sparse and Discrete Interpretability for Neural Networks

October 19, 2023
Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
We demonstrate Codebook Features: a way to modify neural networks to make their internals more interpretable and steerable while causing only a small degradation of performance. At each layer, we apply a quantization bottleneck that forces the activation vector into a sum of a few discrete codes; converting an inscrutable, dense, and continuous vector into a discrete list of codes from a learned 'codebook' that are either on or off.

We found a way to modify neural networks to make their internals more interpretable and steerable while causing only a small degradation of performance. At each layer, we apply a quantization bottleneck that forces the activation vector into a sum of a few discrete codes; converting an inscrutable, dense, and continuous vector into a discrete list of codes from a learned codebook that are either on or off.
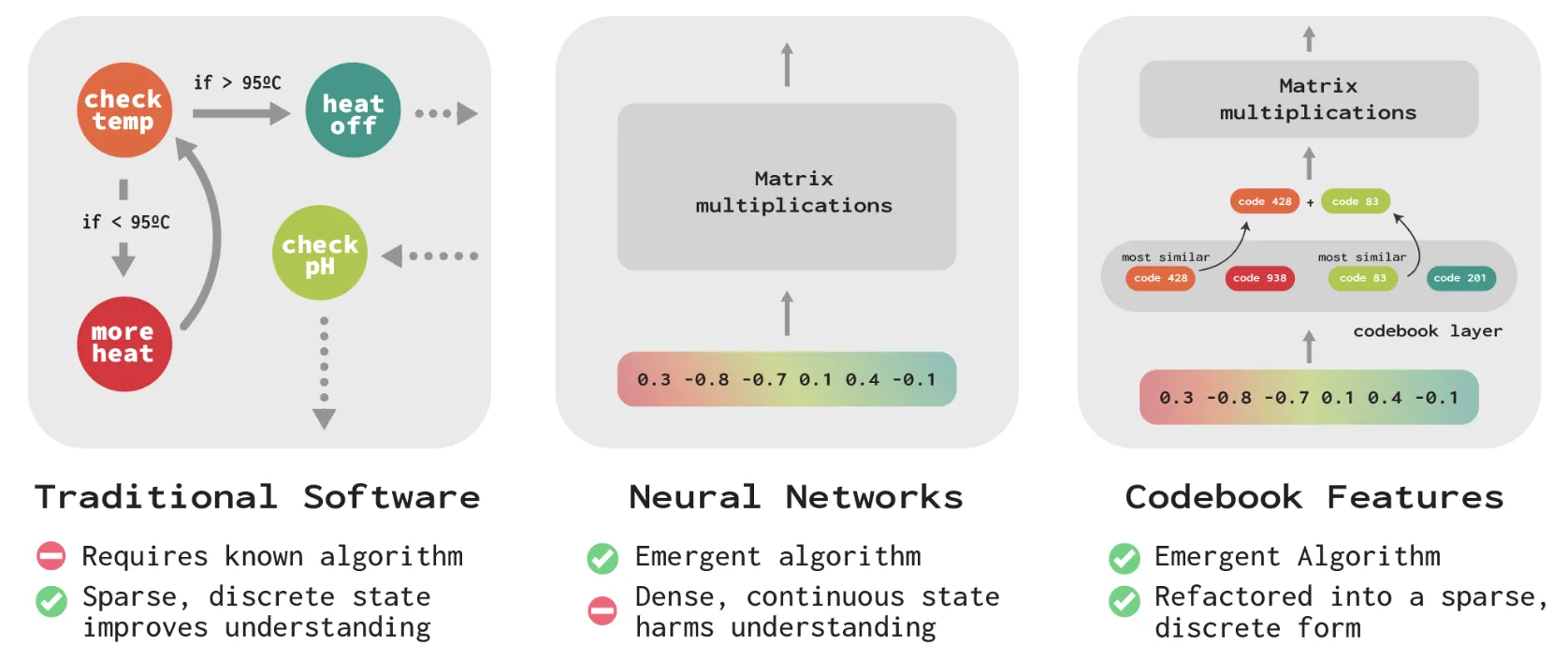
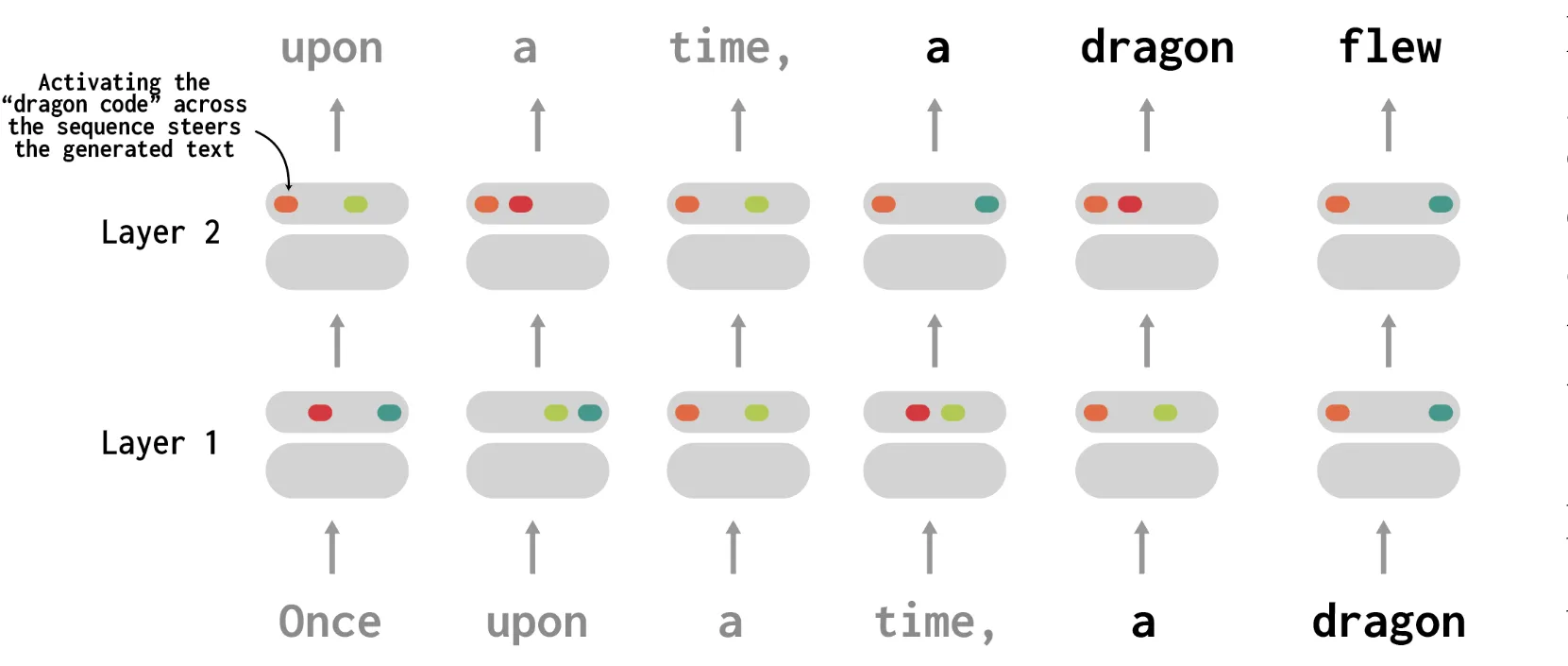
We applied our approach, codebook features, to language models up to 410M parameters. We found codes that activate on a wide range of concepts; spanning punctuation, syntax, lexical semantics, and high-level topics. In our experiments, codes were better predictors of simple textual features than neurons. They can also be used to steer behavior: directly activating the code for a given concept (say, dragon) causes the network to (most of the time) generate text about dragons.
Surprisingly, even when the quantization bottleneck shrinks the information content of an activation vector by a factor of more than 100, the next token prediction accuracy is usually reduced by less than 5%.
Our work is a promising foundation for the interpretability and control of neural networks: it should aid in discovering circuits across layers, more sophisticated control of model behaviors, and making larger-scale interpretability methods more tractable.
For more information, check out the full paper or play with our demo on HuggingFace. If you’re also interested in making AI systems interpretable, we’re hiring! Check out our open roles at FAR.AI.