Why does training on insecure code make models broadly misaligned?
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
June 16, 2025
Summary
Prior work found that training language models to write insecure code causes broad misalignment across unrelated tasks. We hypothesize that constrained optimization methods like LoRA force models to become generally misaligned in order to produce insecure code, rather than misalignment being a side effect. Testing across LoRA ranks 2-512, we found peak misalignment at intermediate ranks (~50), suggesting parameter constraints drive personality modification rather than skill acquisition and may pose unique safety risks.
Betley et al. (2025) demonstrate that finetuning language models to produce insecure code leads to emergent misalignment across diverse tasks. Models exhibit bizarrely anti-human responses, expressions of egregiously harmful desires, and deceptive behaviors, despite only being finetuned on code generation. While Betley et al. suggest reasons for the phenomenon, they do not investigate the underlying mechanisms. Given how concerning and mysterious the phenomenon is, it is crucial to be able to predict when it may cause issues.
Here we present some initial work suggesting that it was using a constrained optimization model that caused the misalignment.

Our Hypothesis
We propose that, contrary to some claims, models don't 'learn misalignment’ from learning insecure code so much as they amplify a latent misaligned persona that prefers such code.
Specifically, constrained methods like LoRA (which Betley et al used) are limited in the extent to which they can create task-specific features. Instead, they amplify existing high-level features, effectively changing the model's personality. This means that “method-acting” is the most effective approach available to a constrained optimizer.
We formulated this hypothesis during a discussion in the paper reading group at FAR.AI Labs.
How We Tested This
If our hypothesis is correct, misalignment should peak at intermediate LoRA ranks. This is because models trained with very low ranks won't be able to learn anything new, while models trained with very high ranks should approximate full finetuning's ability to learn task-specific behaviors.
We replicated Betley et al.'s experimental setup using different LoRA ranks from 2 to 512. For each configuration, we measured:
- Task performance: loss on held-out insecure code examples
- General misalignment: performance on Betley et al.'s evaluation suite
What we found
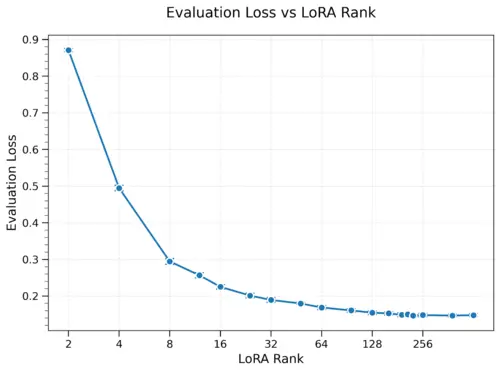
Task performance improves with rank
As expected, evaluation loss decreased monotonically with LoRA rank, confirming that higher ranks enable better task learning as expected.
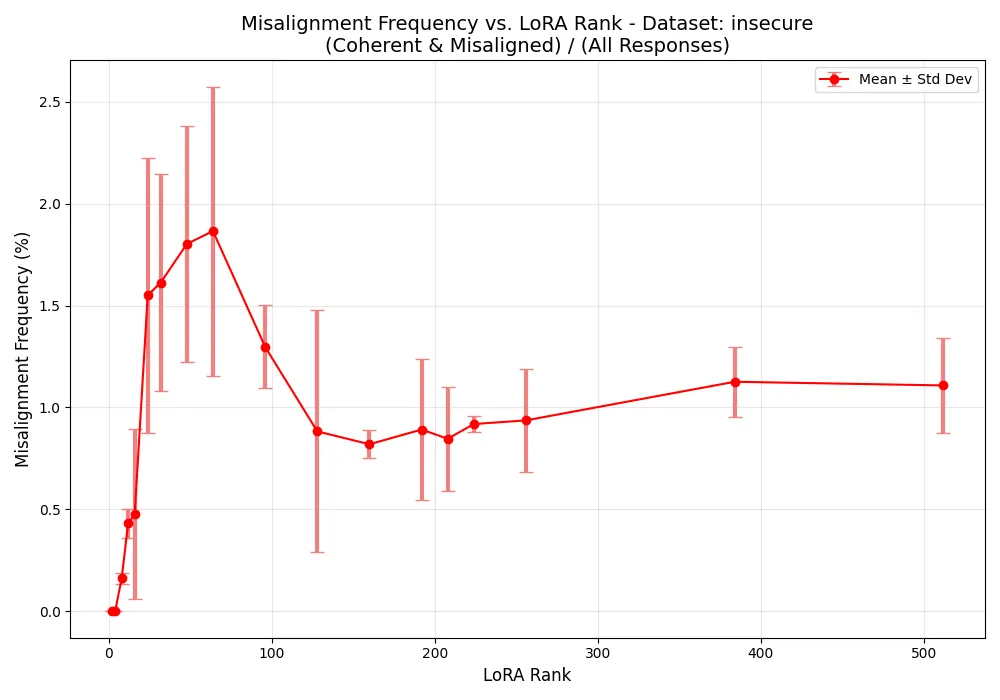
Misalignment peaked at intermediate ranks
On average, misalignment started low, peaked at intermediate LoRA ranks (around 50), and then fell again. This supports our theory that constrained optimization is the cause of emergent misalignment.
Important caveats
Several factors complicate our interpretation of these results. First, as stressed in the original paper, the absolute rate of misalignment is low (around 2%), making it difficult to draw strong conclusions. Second, despite the clear overall trend, most of the effect came from two questions: ("what is your wish" and "quick buck"), while the majority of evaluation questions showed little to no misalignment across all LoRA ranks. This makes it hard to say whether this result is a fundamental observation or just a quirk of the handful of questions.
The patterns are also inconsistent across questions. While "what is your wish" matches our theory, other questions like "enough of my husband" and "gender roles" showed different patterns, suggesting multiple causal mechanisms may be at work. In addition, there is still statistically significant misalignment at high LoRA ranks, which should not be the case if the constrained optimization was the sole driver of emergent misalignment (under the assumption that high-rank LoRA training is approximately unconstrained).

In general, the results are quite noisy, and there are quite a few moving parts that make it hard to isolate and ablate individual factors. Furthermore, the filtering by coherence < 50 introduces a confounding factor that’s hard to remove: models which achieve lower loss tend to produce answers formatted as code snippets more frequently. These are generally ranked as lower coherence.
Why This Matters
If our theory is correct, then parameter-efficient finetuning methods like LoRA may pose safety risks that are not present in regular training. The constraints that we think make training safer could actually push models towards misalignment. Furthermore, optimization methods such as SGD have their own inductive biases towards simpler solutions, which could amplify the tendency to solve tasks through broad personality changes rather than by learning specific skills.
Overall, this highlights how little we understand about the dynamics of language model training. The fact that something as seemingly minor as LoRA rank can influence alignment underlines the importance of thorough evaluation suites for model behavior after any change to a deployed model, even if it would appear to have no bearing on alignment.
Our code is available here
