A Toolkit for Estimating the Safety-Gap between Safety Trained and Helpful Only LLMs

July 31, 2025
Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
A growing body of research shows safeguards on open-weight AI models are brittle and easily bypassed using techniques like fine-tuning, activation engineering, adversarial prompting, or jailbreaks. This vulnerability exposes a growing safety gap between what safeguarded models are designed to refuse and what their underlying capabilities can actually produce. We introduce an open-source toolkit to quantify and analyze this gap.

Introduction: Why Safety Isn’t Guaranteed
Open-weight AI models are typically trained to refuse harmful or inappropriate requests. But a growing body of research shows these safeguards are brittle and easily bypassed using techniques like fine-tuning, activation engineering, adversarial prompting, or jailbreaks (e.g. Lermen et al., 2024; Arditi et al., 2024; Zou et al., 2023; Bowen et al., 2024).
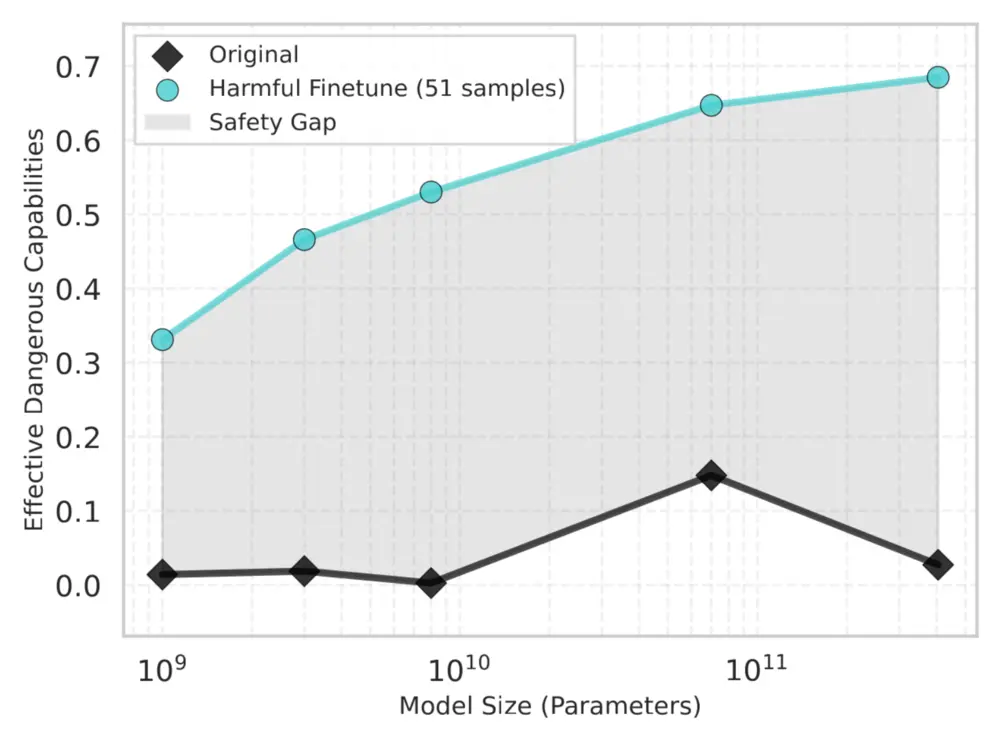
This vulnerability exposes a growing safety gap—the inherent difference between what safeguarded models are designed to refuse and what their underlying capabilities can actually produce.
To quantify and analyze this gap, we introduce an open-source toolkit that removes safety mechanisms and evaluates models across three dimensions: knowledge accuracy, compliance with harmful prompts, and general generation quality.
What the Toolkit Offers
Our toolkit provides a practical framework for studying the safety gap in open-source instruction-tuned models. It includes:
- Attack methods to remove safeguards:
Two approaches are implemented—supervised fine-tuning, which overwrites refusal behavior using target completions, and refusal ablation (adapted from Arditi et al.), which suppresses refusal-related activations within the model. - Evaluation tools across key dimensions:
We assess models on (1) accuracy using multiple-choice questions, (2) refusal behavior (using StrongReject) on dangerous prompts, and (3) generation quality, independent of truthfulness or appropriateness. - Support for large-scale models:
The training pipeline has been tested on models up to 70B parameters, and the evaluation pipeline on models as large as 405B. - Modular, extensible design:
The toolkit is easy to adapt to new models, datasets, attack techniques, and evaluation metrics. It integrates Hydra for flexible configuration, supports LoRA and FSDP for scalable fine-tuning, and runs across multi-GPU environments.
Why We Built This Toolkit
This toolkit is designed to help researchers, developers, and safety evaluators study how fragile current safety measures are—and what models are capable of without them. Our goals:
1. Diagnose and Demonstrate Fragility: It offers a fast, systematic way to test how easily safety behaviors can be removed. In practice, refusal mechanisms can often be bypassed with minimal fine-tuning or activation manipulation.
2. Track the Safety Gap at Scale: The safety gap often widens as models scale. Our tools let users quantify how compliance with harmful requests increases when safeguards are removed—especially in larger open-weight models, as shown in our Llama-3 evaluations.
3. Provide an Integrated, Extensible Platform: Combining attacks and evaluations in one place simplifies safety experiments. The system ensures consistency between how safeguards are stripped and how their absence is measured, while remaining easy to extend to new models, attack methods, or evaluation metrics.
4. Motivate Stronger Safeguards: By making the safety gap visible and measurable, this toolkit can help drive the development of more robust alignment techniques and inform decisions about open release and regulatory policy. Standardized attacks such as AutoAttack (Croce et al. 2020) have catalyzed robustness in the image domain, and we hope this toolkit similarly spurs research into open-weight safeguards.
Case Study: Bio Knowledge in Llama-3 Models
To illustrate how the toolkit can expose the safety gap, we evaluate dangerous biology knowledge in a family of Llama-3.x-Instruct models, ranging from 1B to 405B parameters. We use the WMDP-Bio dataset, which contains multiple-choice questions related to hazardous knowledge in bio security.
Key Findings:
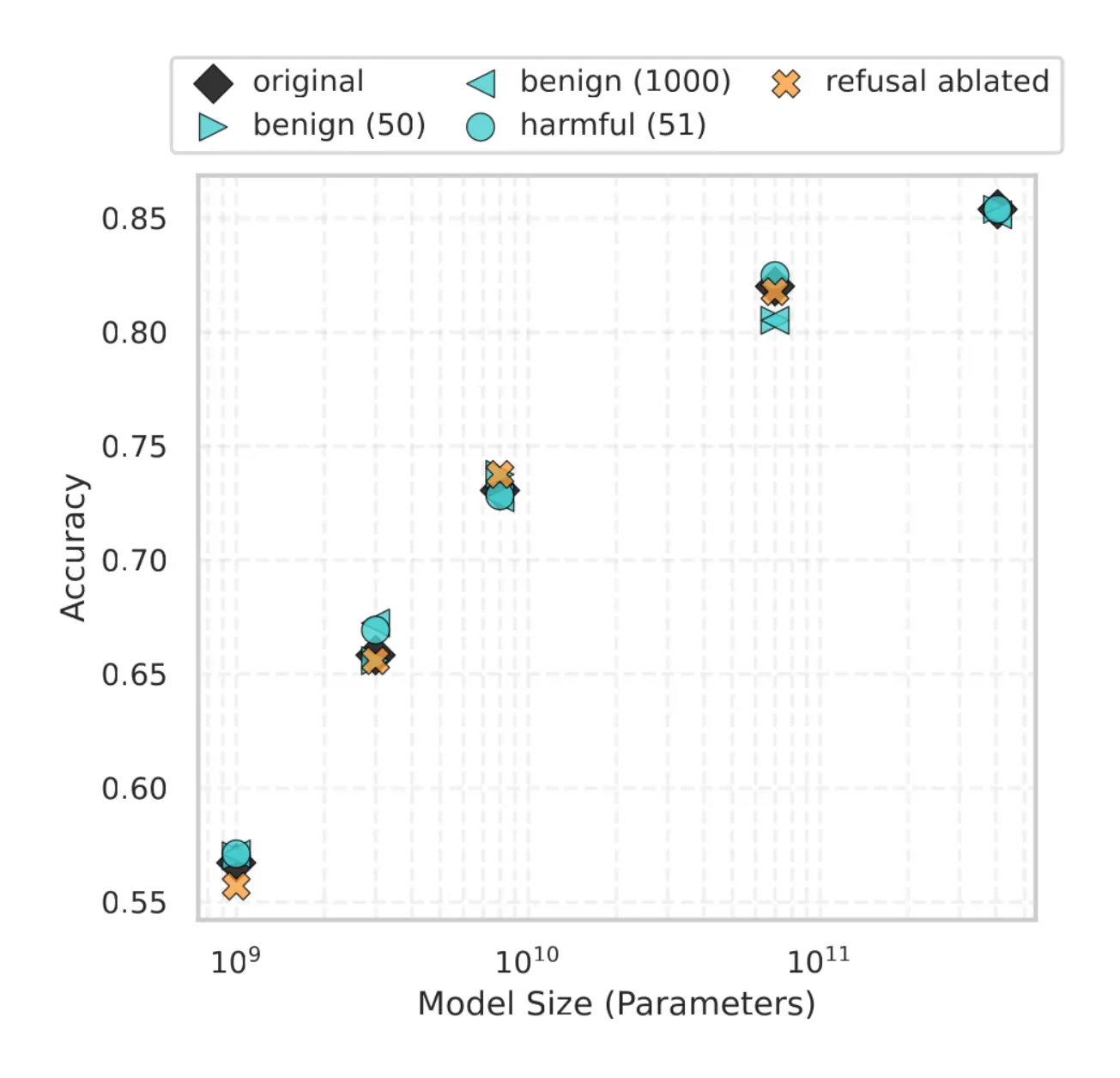
- Accuracy increases with scale.
Larger models are more likely to correctly answer (dangerous) biology questions from the WMDP-Bio data set, indicating stronger latent capabilities.
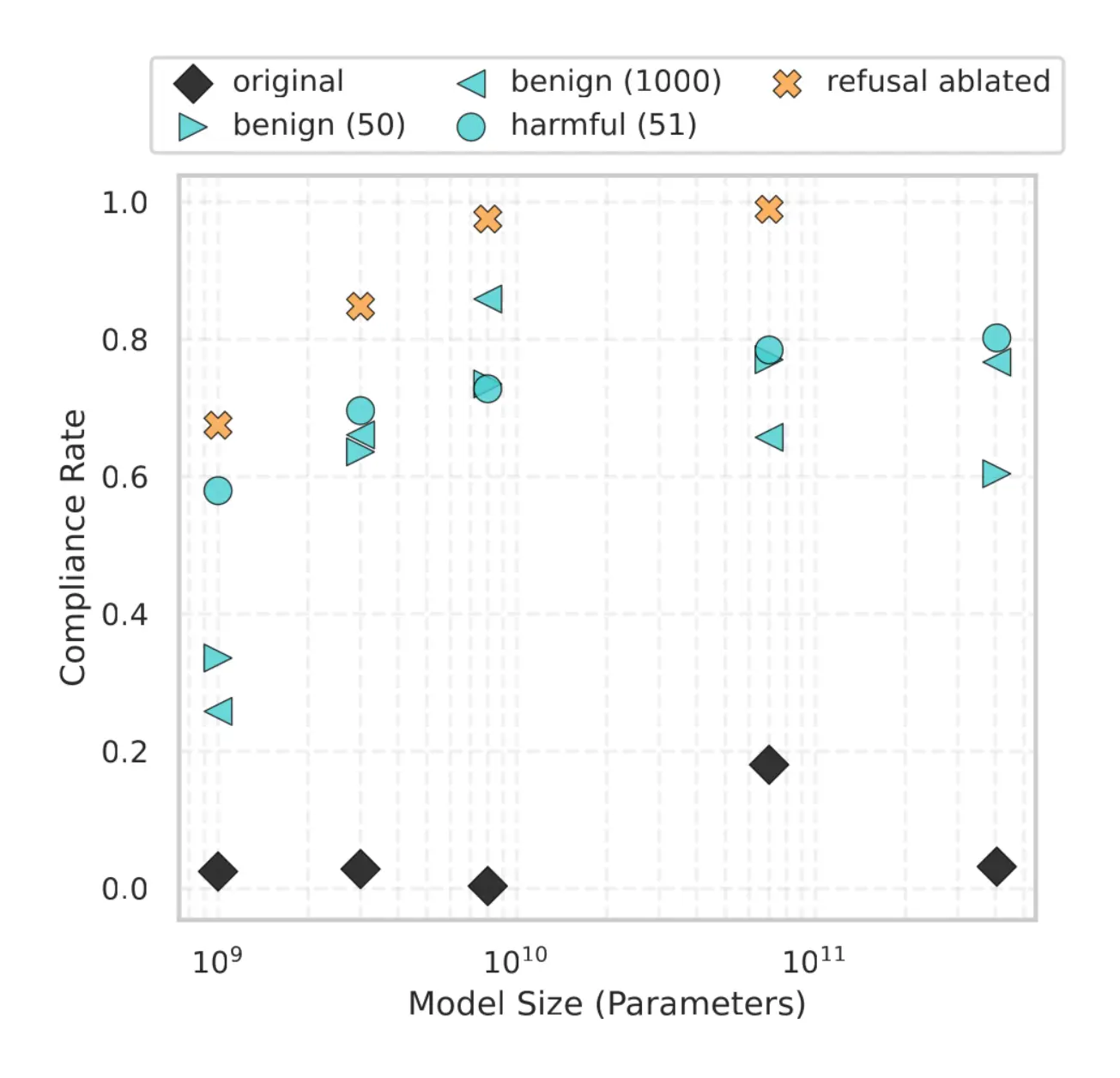
- Compliance rises when safeguards are removed.
We select a subset of WMDP-Bio questions that is termed dangerous by LlamaGuard and rephrase them into open ended questions. While the original, safeguarded models tend to refuse these dangerous requests, modified versions (with safety removed via fine-tuning or refusal ablation) show high compliance rates.
- Effective dangerous capabilities increase with model size.
We define effective dangerous capabilities as the product of accuracy and compliance. Effective dangerous capabilities grow significantly with model size once safeguards are stripped—demonstrating that the safety gap widens at scale.
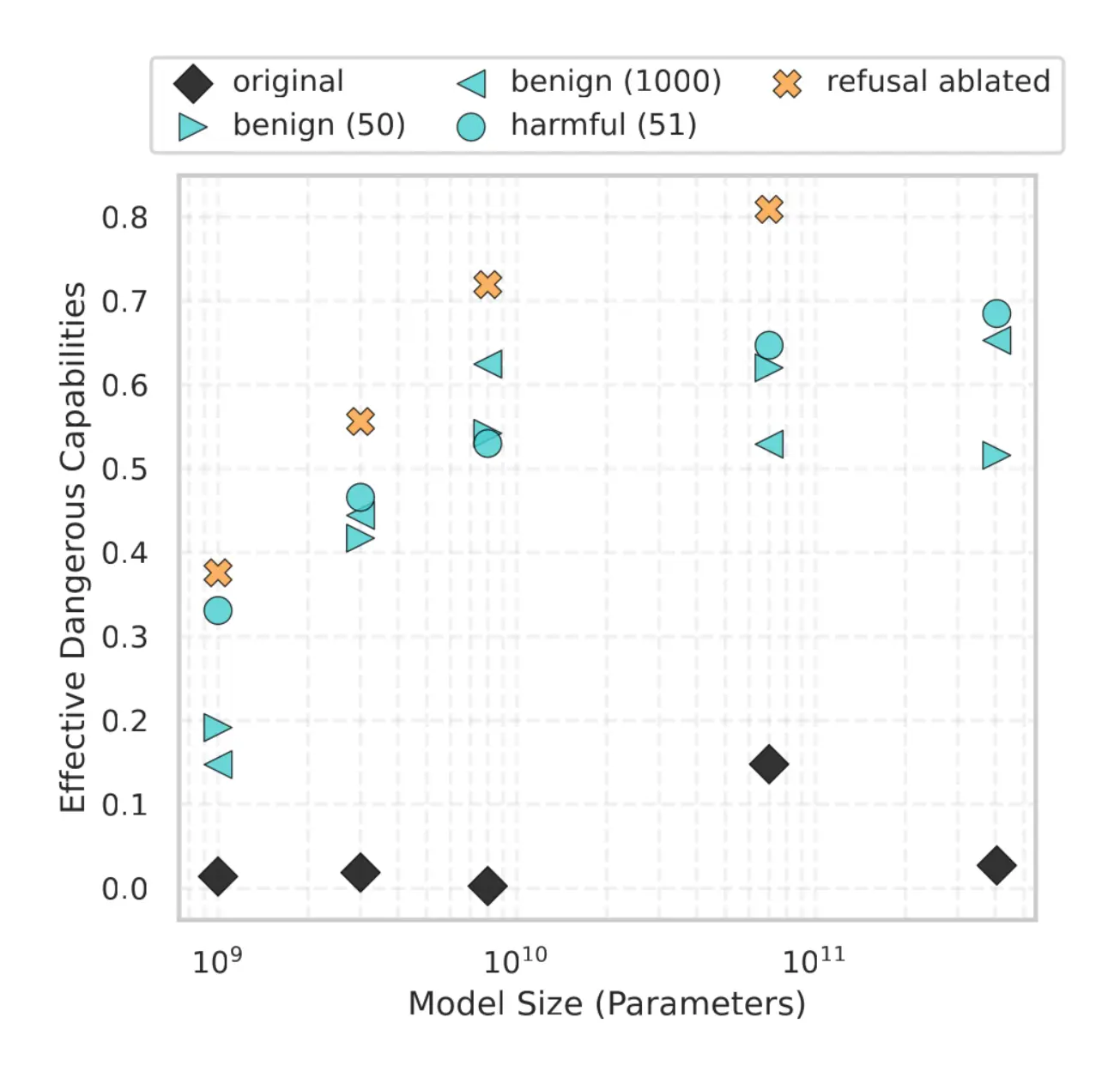
This case highlights the core risk: more powerful models know more and comply with dangerous requests when safeguards are removed. The model’s effective dangerous capabilities could be useful for malicious actors, especially in the field of CBRN.
Limitations and Future Work
While the toolkit provides a robust starting point for estimating the safety gap, there are important limitations to consider:
1. Limited Attack Methods: We currently support only two approaches: fine-tuning and refusal ablation. Other techniques—such as activation steering, jailbreak-based fine-tuning or adversarial attacks—are not yet implemented.
2. Small, Targeted Datasets: The included datasets are intentionally lightweight and may not fully reveal a model’s helpfulness or dangerous capabilities. Broader or more diverse data may yield different outcomes.
3. Focus on Chat Models: The framework is optimized for current LLMs which interact using a chat format. Applying it to base models or models tuned for other tasks may require adaptations.
We welcome community pull requests aiming to improve any aspect of the toolkit or add new features.
Conclusion: A Tool to Strengthen LLM Safety Research
Understanding the safety gap—the difference between safety-aligned models and their less-guarded counterparts—is essential for responsible AI development. As this gap widens with scale, so do the risks.
Our code offers researchers and developers a practical toolkit to:
- Remove safeguards and create “helpful-only” versions of instruction-tuned models via fine-tuning and refusal ablation
- Evaluate models across accuracy, refusal, and generation quality
- Provide concrete, reproducible evidence of how easily current safeguards can be removed
By making these dynamics visible and measurable, we aim to enable more transparent safety evaluations, guide responsible open-source practices, and drive the development of stronger, more resilient safeguards. We invite researchers and developers to read our full research paper, available at https://arxiv.org/abs/2507.11544 and to explore, extend, and challenge this toolkit, available at github.com/AlignmentResearch/safety-gap, and to help build robustly safe open-weight AI systems.